毕氏三元数与复数
所谓毕氏(毕达哥拉斯)三元数(Pythagorean triple),又叫做勾股数,商高数,是由毕氏定理衍生出来的,即直角三角形两直角边的平方和等于第三边的平方。毕氏三元数就是满足方程 $a^2+b^2=c^2$ 的正整数解,例如3,4,5这组解,以下我们用 $(3,4,5)$ 来表示一组毕氏三元数。这里存在一个问题,有没有可能表示出所有的正整数解呢?
假设我们随意取直角边的长度,例如1和2,那么斜边长为 $\sqrt{5}$ ,斜边长度不是整数,那怎么把它变成整数呢,很简单,直接平方一下,可是两直角边就不对了,那怎么解决呢?标题上已经剧透了我们要使用复数,那么,我们可以把斜边看成是一个复数,而两直角边分别是复数的实部和虚部,那么我们就可以把刚刚例子中的直角三角形用 $2+i$ 来表示,那我们对这个复数计算平方,$(2+i)(2+i)=4+4i-1=3+4i$,这个复数的模就是5。哎?我们看到了这是啥?是不是正好表示 $(3,4,5)$ ,这是巧合吗?
Read more...smooth sort与weakheap sort实现
本篇补充smooth sort和weakheap sort,不打算做太多介绍,因为自己太菜不会讲,只作为笔记来记录一下实现代码。smooth sort在接近排序完成的情况下的动态图
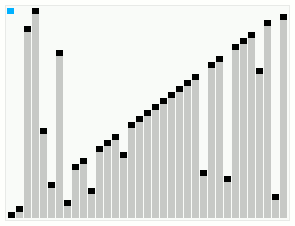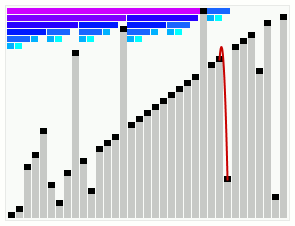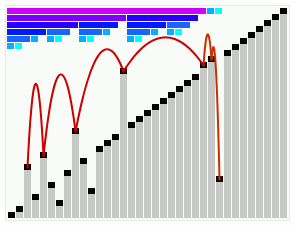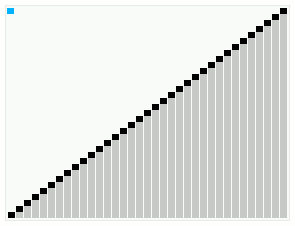
堆排序优化思路
堆排序其实是最不好优化的一个,在数据结构都确定的情况下,优化空间太小,除非优化数据结构本身,但那样就不叫做堆排序了。类似堆排序的还有smooth sort和weakheap sort,有兴趣可以自己查找相关资料。
堆排序原理
堆排序其实是选择排序的优化变种,选择排序是把最大或最小的元素放到最边上,然后不断重复以上过程,堆排序也是如此,只不过堆排序通过构建数据结构,让查找最大或最小元素并放到最边上的速度比选择排序快得多。
首先我们先来介绍什么是堆。堆只是个缩写,全名是二叉堆,是一种完全二叉树,它的特点是二叉堆的父节点元素不小于子节点的元素,以下为二叉堆例图
graph TD;
30-->29
30-->28
29-->24
29-->25
28-->26
28-->22
24-->21
素数判断和因子分解
这里记录的是素数判断 Miller Rabbin 的快速判定算法,而分解使用的算法是 Pollard Rho 的玄学分解算法,这个算法的理论依据是生日悖论,这里不具体讨论这个数学问题,具体讨论看前面链接就可以了。
以下我们分别简要介绍这两个算法的原理
首先这是Miller Rabbin的维基百科介绍页,由于页面是中文,这里不做重复介绍。
下面简要解释一下Pollard’s Rho算法的原理,这是它的维基百科页面
首先我们来定义这样一个函数
$$f(x)=(x*x+c)%n$$
其中n是需要被分解的数,c是一个任意小于n的正整数常数。那么我们给一个初始值x1,通过计算 $f(x1)$ 得到x2,然后去求 $|x1-x2|$ 与 n 的最大公约数,只要结果大于1就找到了分解结果。那如果最大公约数仍然是1,那么就通过刚才的x2求出 $x3=f(x2)$ 并计算 $|x1-x3|$ 与 n 的最大公约数。也就是说,我们可以通过这个公式得到一个数列
Read more...二进制技巧
二进制位运算的技巧特别多,这里就做一份cheat sheet,希望能帮助到大家。不过过于简单的就不列举了
单行表达式
| 作用 | 表达式 |
|---|---|
| 把右边连续的1变成0 | n & ( n + 1 ) |
| 把右边第一个1变成0 | n & ( n - 1 ) |
| 把右起第一个0变成1 | n | ( n + 1 ) |
| 把右起连续的0变成1 | n | ( n - 1 ) |
| 取右边连续的1 | n ^ ( n + 1 ) |
| 去掉右起第一个1的左边 | n & -n 或 n & ( n ^ ( n - 1 ) ) |
| 高低位交换,前x位 | ( n << x ) | ( x >> ( 32 - x ) ) |
| 有符号整数计算绝对值 | ( n ^ (n >> 31) ) - (n >> 31) |
插入排序与希尔排序优化思路
本篇针对插入排序和希尔排序来讲优化思路,有部分内容因为前一篇文章已经有交代,这里不重复,如果你还没有看,请先看前一篇。我们来看插入排序的动图演示

插入排序保证前面一块是有序的情况下,新增的一个元素通过向前交换到合适的位置,所以叫做插入排序。
插入排序基本实现
我们先来看插入排序的基本实现
void insert_sort(sort_element_t * beg, sort_element_t * end)
{
for (sort_element_t* i = beg + 1; i < end; ++i)
{
sort_element_t val = *i;
sort_element_t* j = i;
for (; j > beg && val < j[-1]; --j)
{
*j = j[-1];
}
*j = val;
}
}
插入排序即使不做任何优化,效率也明显高于上篇所说的冒泡排序和选择排序。那么按照惯例,先上双向看看效果
Read more...选择和冒泡排序优化思路
本篇针对两种最基本的排序(冒泡、选择)来讲优化思路。越是简单的东西反而可能存在你越想不到的优化点。但是在开始之前,先给不了解的人讲一个设计原则的问题,我们在设计排序接口的时候,最为常见的有
void sort(type arr[], int len)
也许你也见过
void sort(iter beg, iter end)
这时候问题就来了,很多人会错误地把end认为是最后一个元素,其实不然,这两接口可以相互转换,例如我们可以写 sort(arr, arr + len) ,这样写很自然对不对,但如果你认为end是最后一个元素,那你就不得不改成 sort(arr, arr + len - 1) 。事实上,这类的接口我们需要一个统一的原则,就是左闭右开区间原则,即beg就是首个元素,而end是最后一个元素+1,即end是作为结束标志,不应该把end算在范围内。接下来下面所有的接口写法,都是以
void sort(iter beg, iter end)
这种方式写的,至于这样写有什么好处,接下来我们就看示例。
选择排序
Quick sort(快速排序)杂谈 1
我们现在使用的排序,很大比例在使用quick sort,因为它是平均速度最快的排序,但与此同时它可能也是坑最深的排序,现在我们就来讨论讨论它,因为内容较多,我计划写多篇,本篇是第一篇。
快排的思路
我们先来介绍一下快排的思路。快排的思路其实很简单,在数组中选一个元素,我们就称呼这个元素为pivot,通过与这个元素的比较,把数组划分成不比pivot大的在一边,不比pivot小的在另一边,于是就分成了两个更小的数据,对它们分别再排序就行了。但是,这个描述特别的含糊,首先是怎么选中间元素,这里面有很多不同的做法。然后就是划分了,这个划分方法非常的多,水也特别深,这里主要介绍最为常见的划分方法。
Read more...Mingw 的 Bug
这个问题最早的时候是今年8月,我在测试排序算法的速度,发现mingw上总有点不一样,而linux下的gcc是正常的,也在群里问过人,没人明白到底怎么回事,先描述一下当时遇到的情况。
一开始我使用std::random_shuffle打乱数组并用std::sort排序,在VS上并没有发现什么问题,gcc也正常。但在mingw上,这样打乱的数组排序所花的时间,比起其它打乱方式的,例如直接赋值一个随机数的方式,要明显慢了近1倍,这个诡异的问题一直没想通是为啥。当时觉得可能是std::sort对这种方式打乱的数据排序有点问题导致变慢。
后来,为了和std函数脱钩,我自己重新写了随机数函数和random_shuffle函数,结果发现我的random_shuffle函数打乱的结果,std::sort的时间是完全正常的,非得std::random_shuffle才会出现两倍的情况,一时间我还以为是我写的有问题,还更换了不同随机函数,怎么也发现不了原因,终于把怀疑转向std::random_shuffle,我就对这个函数的执行结果输出到文件,这一输出立即把我搞懵了,输出的结果分布特别有规律,初值我用的是arr[i] = i,打乱后结果前32768个数都是数组里最大的数值,一时没明白怎么回事,难道它的实现很不寻常吗?我就去翻了一下源代码,在cppreference下源代码长下面这样:
博客第一文,附hugo表格的坑
第一次使用这个hugo就遇到一堆坑,主题并不是随便用,会有SHA-256校验,而在windows平台下用git,clone下来会把\n自动换成\r\n从而导致主题应用失败,服了。
另一个坑就是hugo的表格,你不能像以下这么写
a|b|c
-|-|-
1|2|3
这样hugo的引擎是不认为这是表格,正确的做法是改成下面这样
Read more...